
Spurious Rewards: Rethinking Training Signals in RLVR – Fast Overview
Yaniv’s and Mike’s Daily Paper: 09.06.25


One-line takeaway.
Even completely noisy or adversarial rewards can unlock big math-reasoning gains but only for models whose pre-training already hides the right skills.
Why this matters?
RL with Verifiable Rewards (RLVR) is the state-of-the-art way to teach LLMs step-by-step reasoning. The paper asks a blunt question: how much of that “reward” signal do we actually need? Spoiler: sometimes almost none.
Experimental recipe:
The authors fine-tuned the Gwen-2.5-Math-7B model on a math dataset (DeepSeek-Math) using GRPO for 150 reinforcement learning steps. They tested five types of reward signals:
Ground-truth reward: A standard signal where the model gets +1 only if the final answer is correct.
Majority-vote reward: The model generates 64 responses, and the most common one is treated as the correct answer for reward purposes.
Format reward: The model is rewarded just for including a boxed math expression (like \boxed{}), regardless of whether the answer is actually right.
Random reward: The reward is assigned randomly with a 50% chance for +1 or 0, completely independent of the answer.
Incorrect reward: The model is rewarded only when it gives an incorrect answer.
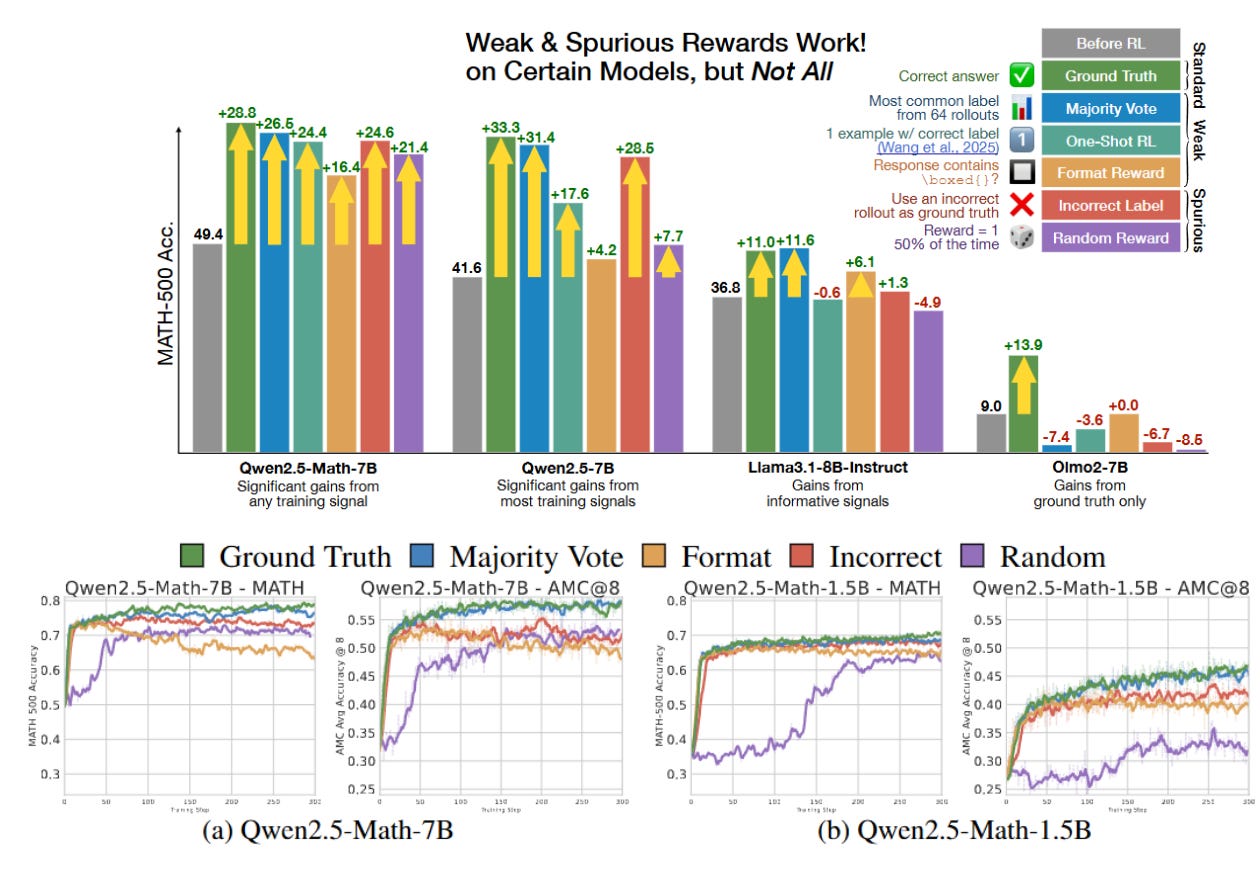
Surprisingly, all of these reward types led to major performance gains — even the random and incorrect rewards brought the model close to the performance of ground-truth training.
What they found?
Qwen models soar regardless of reward: every weak/spurious signal above gives 16–26 pp gains, nearly matching gold supervision. Llama 3 and OLMo 2 barely move unless given the real label .
Hidden skill = code reasoning: Qwen-2.5-Math already solves 65 % of problems by writing inline Python (without execution). RLVR pushes that to ≈ 90 %, and accuracy rises in lock-step.
Lang → Code switch explains the lift. 58 % of Qwen’s gain comes from questions that flip from pure language to code reasoning during RLVR .
Random rewards work via optimizer bias. GRPO’s clipping term preferentially up-weights high-probability tokens, amplifying whatever strategy the model already prefers; ablate clipping and the random trick stops working .
No free lunch across models. Llama and OLMo lack useful code priors, so the same spurious signals either help little or hurt .
Take-home message
RLVR often surfaces, rather than teaches, reasoning that pre-training has already seeded. This is in line with another recent paper showing RL reasoning results can be achieved with a single training sample. For reward design and future benchmarks, verify results on multiple model families and not just Qwen.
https://github.com/ruixin31/Rethink_RLVR/blob/main/paper/rethink-rlvr.pdf
 | A guest post by
|