

Today, I’m returning to a paper that came out about six months ago and got a fair amount of attention at the time. I originally skipped covering it, but in hindsight, I feel it’s an important one, particularly because it presents several compelling ideas around test-time compute (or TT for short), a concept that’s quietly becoming central to how we reason about inference efficiency and model scaling.
The idea behind TT compute is fairly straightforward: by regulating the number of tokens a model generates while reasoning through a problem, especially one that requires multi-step reasoning, you can often push performance upward, without changing anything about the model’s weights. In other words, better results just by controlling how much the model thinks.
This is the core of the paper’s contribution. It explores how simple interventions at inference time can improve accuracy on difficult tasks, and it does so using a deliberately small and clean setup. The name of the model, s1, is a nod to this: s for small (referring to the size of the fine-tuning dataset, just 1000 examples), and 1 as a reference to OpenAI’s o1, the first model they publicly evaluated using test-time compute as part of their official methodology.
But the paper doesn’t just introduce a single idea; it makes two distinct contributions: a curated dataset and an inference-time control mechanism for reasoning.
A Dataset for Deep Reasoning
The authors begin by constructing a dataset of difficult questions across multiple domains: mathematics, biology, chemistry, physics, and more. To ensure the questions were genuinely hard, they ran them through two models, Qwen 32B and Qwen 7B, and then evaluated their answers using Claude 3.5. Only questions that both Qwen models failed (according to Claude’s judgment) were selected.
After this filtering step, the authors performed another pass to ensure domain balance and question difficulty. For each domain, they selected the examples that required the longest answer chain on the assumption that longer solutions correspond to more complex reasoning steps. This final dataset was used to fine-tune the Qwen 32B model via supervised fine-tuning (SFT), resulting in the s1 model.
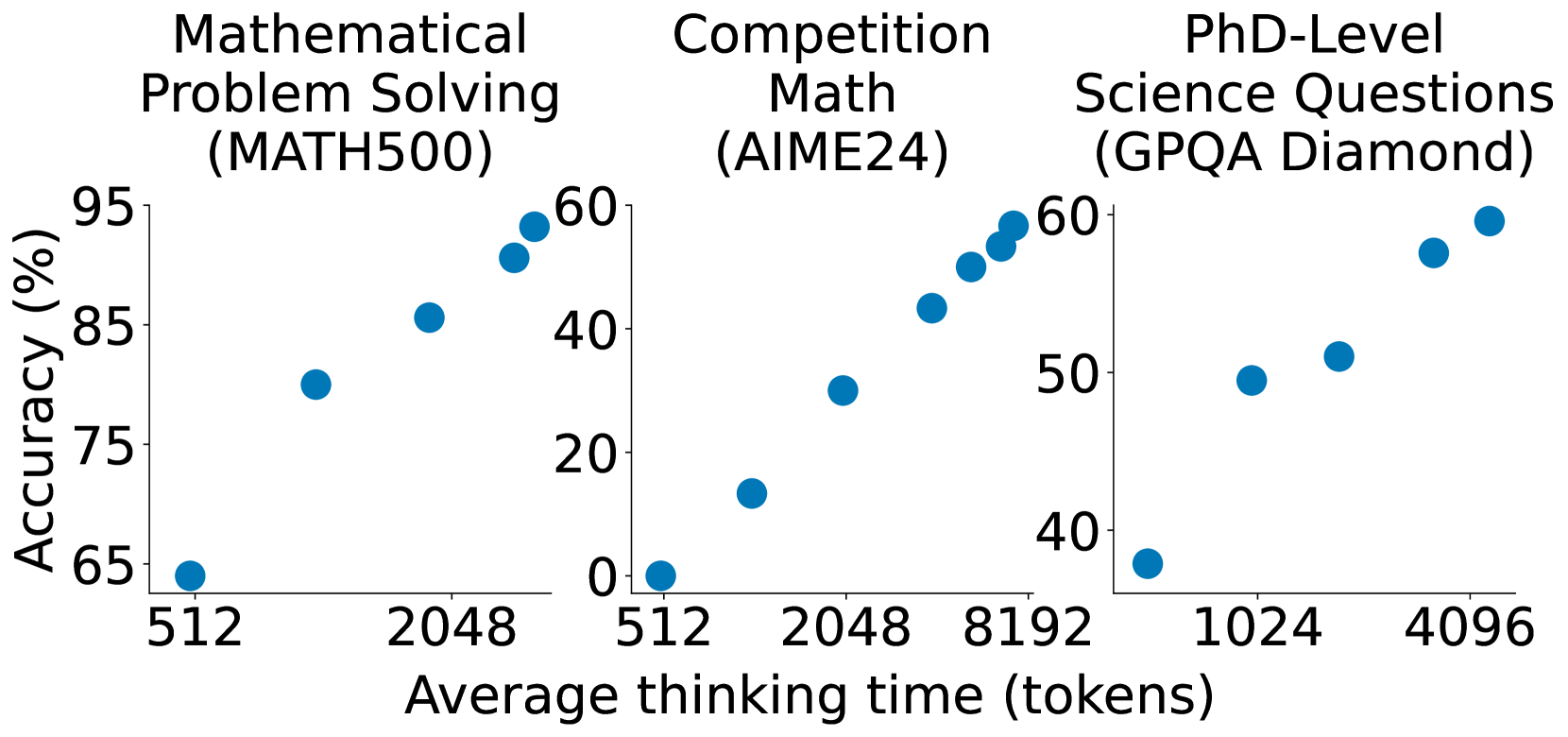
Test-Time Compute as a Control Problem
The second and more novel contribution lies in how the authors handle inference. Instead of passively letting the model generate an answer, they inject control tokens that regulate the length and structure of its reasoning chain.
Two special tokens were introduced: "wait" and "end of thinking". These tokens effectively let the inference engine pause or cut the reasoning process:
If the model was about to output an answer too quickly, a "wait" token was injected to encourage it to continue thinking.
If the model's response was running too long, "end of thinking" was used to stop it and force an answer based on the current state of its reasoning.
This creates a form of “reasoning budget” management. The paper shows that encouraging the model to think longer usually leads to better performance but only up to a point. After about four "wait" insertions, the gains plateaued. Interestingly, shortening the model’s reasoning chain didn’t significantly degrade performance (at least within context window limits), suggesting that reasoning efficiency saturates fairly quickly.
What This All Tells Us
What’s remarkable is that the s1 model, trained on just 1,000 examples, achieved performance close to that of much larger models trained on far more data. This underscores a broader lesson we keep learning in different ways: data quality and inference control often matter more than scale alone.
And importantly, this paper reinforces the idea that test-time compute is not just a reporting detail, but it's a tool. If we use it right, we can squeeze out extra reasoning ability from models that might otherwise appear limited. For those of us thinking about how to scale reasoning safely, efficiently, and interpretably, the combination of data curation and test-time control seems like a promising direction.