


Representation Alignment for Generation: Training Diffusion Transformers is Easier than You Think
Deep Learning Paper Review: Mike's Daily Article 16.02.25

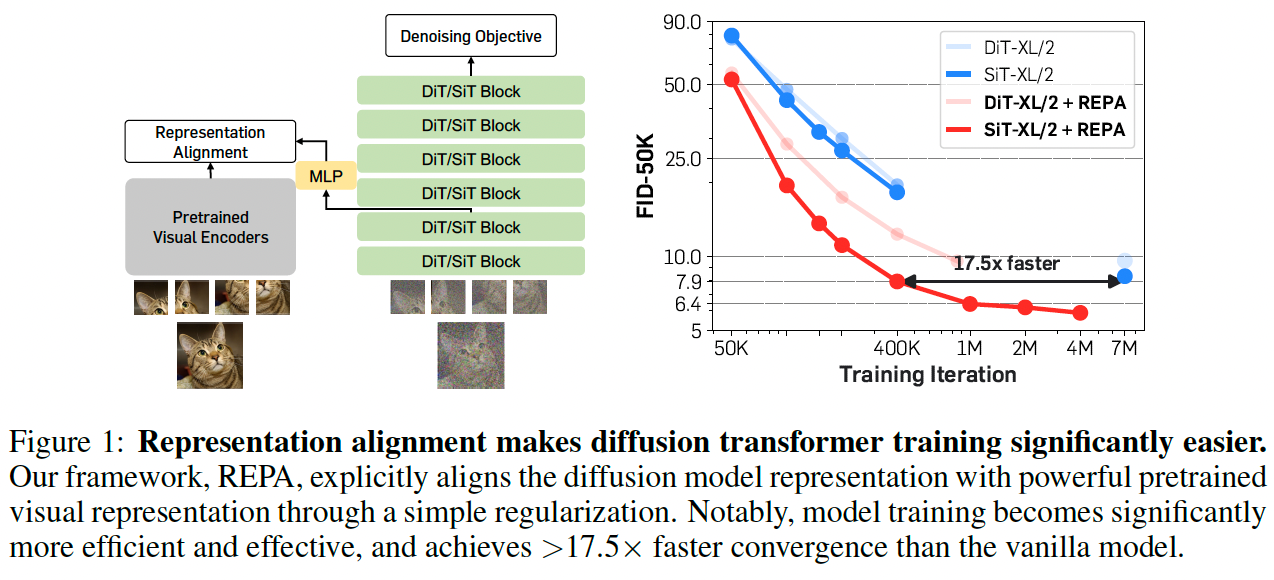
Taking a brief break from LLMs to review a paper about generative diffusion models. The paper proposes a rather intuitive method for improving the performance of these models by adding a regularization term that "aligns" the model's internal representations with those of powerful encoders like DiNOV2. This alignment improves the quality of images generated by the model.
Let's start with a brief background on generative diffusion models. These models are trained to generate images (for example, given a textual description) through gradual noise removal. The model starts with pure noise (typically Gaussian) and slowly transforms it into an image (or data from another domain). The model is trained on noisy images with different noise levels (=iterations), where during training the model learns to remove a small amount of noise (from iteration t to iteration t-1). The choice of hyperparameter t for the noise process is critical to the generation quality of the trained model.
This process (noise addition) can be described using differential equations of probability flow that describe the change (gradient) of the noisy data with noise rate/velocity that we'll denote as vt (the solution to this equation is distributed according to the noisy data distribution). The noise rate can be estimated with the model (=network) based on noisy data samples and t. Then, the probability flow equations can be solved with the estimate of vt (in reverse direction - i.e., starting from pure noise) using Euler's method, for example. These methods are called stochastic interpolands. Note that there are methods based on numerical solutions of stochastic differential equations that describe data changes as a function of the score function, which is the logarithm of the noisy data distribution function.
Okay, after this complexity things get a bit easier. Diffusion models today are mostly latent models where generation occurs in the data representation space. This means the model is trained to recover a latent representation from noise, and then the decoder is applied to construct an image from the recovered representation. The representation of the initial image is created by the encoder. The authors argue that the noisy latent representations aren't "strong enough," meaning they less effectively reflect the semantic aspects of the image.

The authors propose to enrich these representations by adding a regularization term aimed at bringing these representations (of noisy images) closer to the representation produced by a strong encoder (like DINOV2). This loss is added to the regular diffusion model loss, and it's claimed to improve the quality of generated images and contribute to training stability.
https://arxiv.org/abs/2410.06940