


Random Teachers are Good Teachers
Mike's Daily Paper Review: 15.06.25

An old but very interesting paper at least in my opinion…
This paper presents an interesting and deeply counter-intuitive finding that challenges foundational assumptions in the fields of knowledge distillation and self-supervised learning (SSL). The authors demonstrate that a "student" model can learn high-quality representations by distilling knowledge from a "teacher" network whose weights are completely random and untrained. The work dismantles the standard "teacher-student relationship" to isolate and study the dynamics of learning with knowledge distillation, revealing a process similar to implicit regularization that is not dependent on the teacher possessing any actual "knowledge."
As mentioned, the main goal of the paper is to investigate the dynamics of knowledge distillation. The paper broadly examines two knowledge distillation regimes: with labeled data and without labeled data (label-free).
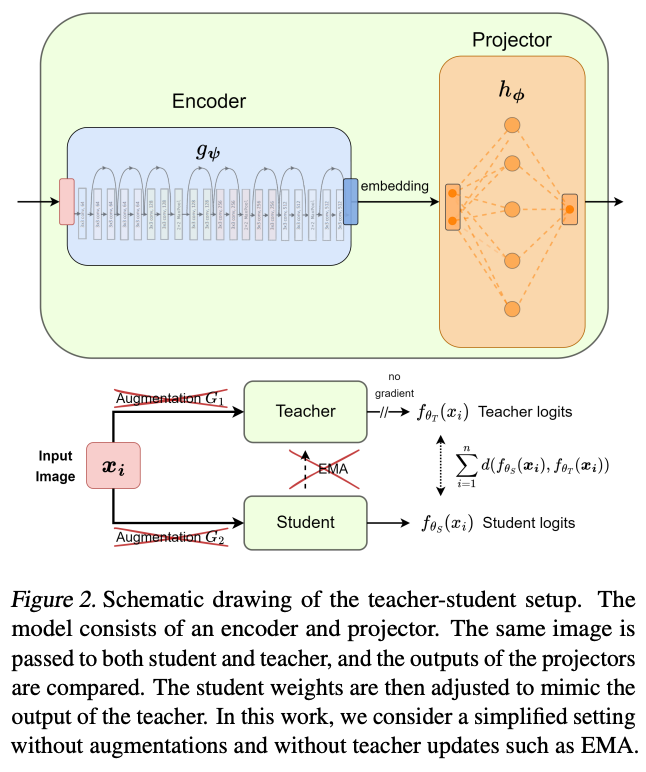
The core of the paper's contribution lies in its elegantly simple experimental setup. The authors create a scenario designed to remove various confounding factors that are typically credited with the success of distillation and SSL methods.
No "Dark Knowledge": The teacher network is initialized randomly and is then "frozen." It is never exposed to the training data or labels, meaning it contains no learned information about the task or the data distribution. The student's goal is simply to minimize the KL-divergence between its output distribution and the teacher's static, random output (though sometimes the student's loss on the data is also added).
No Data Augmentation: Unlike mainstream SSL methods, this work intentionally removes all data augmentations. This ensures that the learned invariances do not stem from the explicit inductive biases introduced by techniques like cropping, flipping, or color jittering.
No Labels: The entire distillation process is fully unsupervised and label-free. The true class labels are only used at the very end to evaluate the quality of the learned representations via linear probing that is, training a linear classifier on top of the frozen representations from the student's encoder.
This minimalist framework ensures that any observed learning effect is attributable solely to the interaction between the model's architecture, the natural data distribution, and the gradient-based optimization dynamics of the teacher-student setup.
The results of the experiment are very surprising. The student network consistently and significantly outperforms its random teacher in terms of linear probing accuracy across many datasets (such as CIFAR-100, STL10, TinyImageNet) and various architectures (such as ResNet, VGG). In other words, the data is more important than the teacher.
Another finding in the paper is the "locality phenomenon": the initial proximity of the student's weights to the teacher's is critical for successful learning. The authors investigate this by initializing the student's weights as a convex combination of the teacher's weights and a set of random weights, controlled by a locality parameter α. When α is close to zero (meaning the student starts almost identically to the teacher), learning is fastest and the final performance is highest (here the student has the same architecture as the teacher - this is not a practical scenario but is interesting for investigation).
This finding suggests an interesting geometry of the loss surface. The teacher's parameterization, θ_T, constitutes a trivial local minimum where the distillation loss is zero. However, the optimization process does not remain there. Instead, it finds a nearby, non-trivial local minimum, θ_S, which corresponds to a region with much higher accuracy (for the training dataset, meaning better representations). Visualizations of the landscape reveal that the teacher often sits within a sharp, "asymmetric valley." The student model appears to escape the trivial solution by moving towards the "flatter" side of this valley, a region whose geometry is known to correlate with better generalization.
Perhaps the most profound finding is that a student checkpoint, developed entirely without labels (only knowledge distillation), exhibits structural representations that were previously thought to appear only in the early stages of supervised training. That is, the student network approaches the teacher (even a random one) when it has "a winning ticket inside it" namely a small subnetwork that knows how to do the same thing.
Emergence of the Lottery Ticket Hypothesis: The authors found that even at the first checkpoint, the student contains a "winning lottery ticket", a sparse subnetwork that can be retrained from its initial weights to achieve high accuracy on a supervised task. A randomly initialized network does not have this property; it appears in supervised networks only after several training epochs. This implies that distillation from a random teacher guides the network to a parameter configuration that is already structured for efficient learning.
Linear Mode Connectivity: Typically, when an early student checkpoint is used as an initialization for several supervised training runs (each with different mini-batches), the resulting solutions are usually "linearly connected." This means one can linearly interpolate in the weight space between any two of these solutions without encountering a high loss barrier along the way. This stability indicates that the student has already converged to a "wide, flat basin" in the supervised loss landscape, effectively bypassing the chaotic initial phase of supervised optimization.
The paper presents a compelling case that the success of teacher-student frameworks is not solely attributable to the transfer of "dark knowledge" from a trained expert. Instead, the paper reveals that the implicit regularization created by the learning dynamics is a powerful engine for learning strong representations in its own right. By demonstrating that a network can develop sophisticated structural representations (like "winning lottery tickets") from a completely random signal, the authors force a re-evaluation of the fundamental mechanisms behind self-distillation and SSL. The work provides a testbed for future work aimed at demystifying the "early phase" of neural network training and the intricate geometry of their loss landscapes.