


O1-CODER: An O1 Replication for Coding
Mike’s Daily Deep Learning Paper – 09.04.25

I finally got around to reviewing this paper that caused quite a stir when it came out. The authors’ explicit goal is to replicate OpenAI’s O1 model, but focused specifically on coding tasks. The paper uses RLHF techniques combined with a self-play method where the model learns from data it generates itself. It starts from a dataset of coding questions and their corresponding answers (i.e., code 😊).
The core idea of the paper involves 4 main stages.
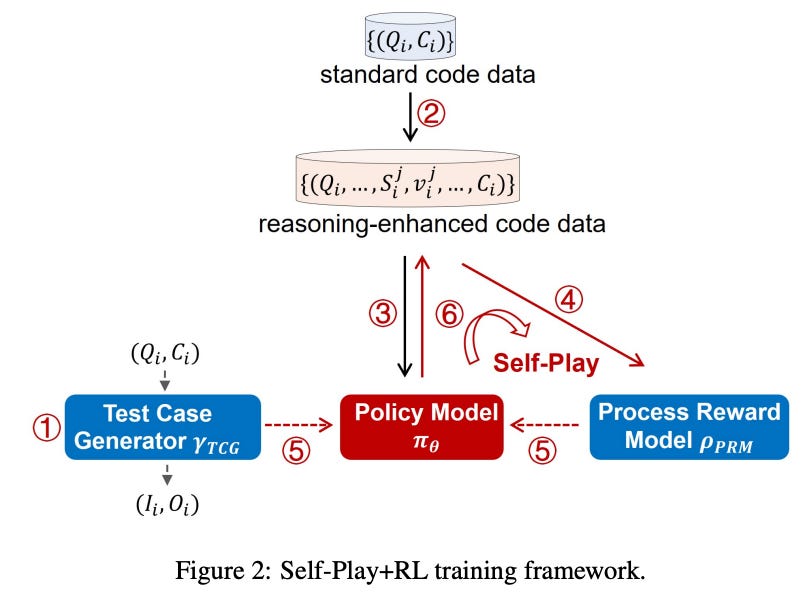
Stage 1: The authors build a tool (not described in much detail) that generates comprehensive tests for a given coding question and its correct solution. This tool (called TTG) will later be used to estimate the reward for code outputs produced by O1-CODER.
Stage 2: Using MCTS (Monte Carlo Tree Search), the model constructs reasoning chains for examples in the dataset. MCTS is a planning algorithm for decision-making that samples the state space (tokens, in our case) to estimate the reward of different possible actions. It incrementally builds a search tree, choosing at each step to expand the branch (token sequence) that looks most promising, balancing exploration of new paths with exploitation of known good ones. Each path (i.e., reasoning chain including a proposed solution) gets a reward of 1 or 0 from TTG (pass or fail all tests).

Stage 3: The model undergoes supervised fine-tuning (SFT) on reasoning chains that led to correct solutions (with reward 1).
Stage 4: Iterative self-play training begins. In each iteration, the training dataset is enriched with new examples generated by the model itself. The process involves either SFT on correct-answer chains (excluding iteration 0) or RLHF training using DPO (Direct Preference Optimization) on pairs of positive and negative examples.
Then, the model generates new reasoning chains (excluding the final answer), and a Process Reward Model (PRM) scores these partial solutions. The model then completes the answer from the reasoning chain, and new tests are generated for the question (since the correct answer is known — likely because the questions come from a benchmark dataset).
The reward is computed by running the tests on the model’s generated code: 1 if all pass, 0 otherwise. This is then combined with the reasoning rewards via an aggregation function. The model is trained to maximize this combined reward using some RL method (possibly regularized, though the paper doesn’t go into details).
Finally, new examples are generated using the updated model, added to the dataset, and Stage 4 is repeated (self-play loop).
Really interesting paper…
https://arxiv.org/abs/2412.00154