


Memory Layers at Scale
Mike’s Daily Deep LearningArticle: 08.05.25

This paper caught my eye because it uses the word “memory” in the context of language models. Even today, when you interact with ChatGPT, Claude, or other models, you're not just speaking to a standalone language model—you’re interacting with a full system that already includes memory layers (often implemented as Retrieval-Augmented Generation or caches). This paper proposes a neural network layer that functions as a memory mechanism—allowing both storage and retrieval based on a query.
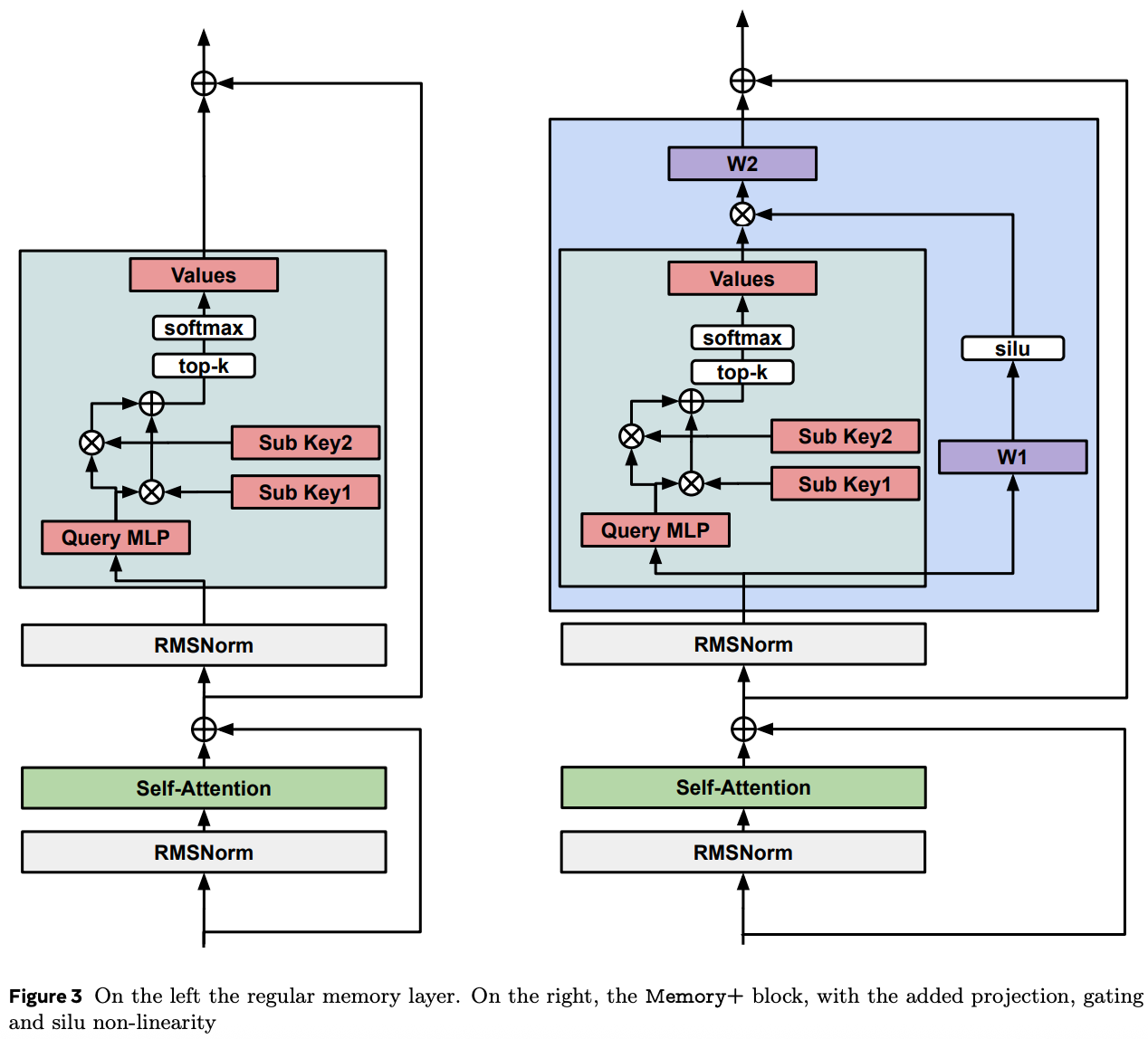
This memory layer is conceptually similar to a transformer block, but with a key difference: instead of attending to all vectors in memory, it retrieves only those relevant to a query vector q. In other words, rather than mixing over the entire memory, the model selects the top k vectors most similar to q. This mechanism resembles a Mixture of Experts (MoE), where only a subset of feedforward (FFN) submatrices are activated. The difference is that in MoE, the “experts” are predefined FFN submatrices, while in the proposed method, any combination of FFN columns can be selected dynamically.

Given a query vector q, the model selects the top k most similar vectors from memory. These are then combined with a value matrix V (the paper doesn’t detail exactly how—so I suspect it’s a standard dot product). The result is then multiplied by a learned matrix W₁ (which has become quite popular recently) multiplied by the self-attention block output (it precedes the memory retrieval block) and then after the SiLU activation is applied to it. That output is finally multiplied by another learned matrix W₂.
Because we want to store a large number of vectors in memory, computing all similarities with q can be computationally expensive. As is common nowadays, the authors shard the memory across multiple GPUs, compute similarities in parallel, and then merge the top results globally to select the most relevant memory vectors. Naturally, each GPU holds a smaller memory matrix, and the query vector q is also split into sub-vectors across GPUs.
This layer can be combined with transformer blocks in language models, but I see no reason it couldn’t also be integrated with other architectures like Mamba. A light, enjoyable read—and along the way, I discovered a neat trick for efficient retrieval from distributed GPU memory.