


Memorization to Generalization: The Emergence of Diffusion Models from Associative Memory
Mike’s Daily Deep Learning Paper Review: 17.04.25

Okay, continuing with a deep theoretical article on generative diffusion models. The central contribution of this paper is a precise reinterpretation of diffusion models as stochastic, overparameterized associative memory systems, particularly those that share structure with modern Hopfield networks. The core insight is that the behavior of diffusion models across varying data regimes — specifically the transition from memorization to generalization — mirrors the dynamics of Hopfield-type networks as they move past their critical memory capacity.
In classical associative memory models like Hopfield networks, the energy landscape is shaped by the patterns stored in memory. When the number of stored patterns is below the theoretical storage limit, each memory corresponds to a stable fixed point — an attractor — in this energy surface. As the number of stored patterns approaches the capacity limit, interference between patterns leads to the emergence of spurious attractors. These are stable points not corresponding to any training pattern, but often lying close to linear combinations or interpolations of the stored set.
This paper observes that diffusion models — which learn a time-indexed score function for denoising — implicitly define an energy functional over data space at each time step. Specifically, the score function learned during training can be interpreted as the gradient of the negative log-probability of the data at that time step, which aligns with the gradient of an energy-based model. When written out, this energy turns out to have the same structure as that of modern Hopfield networks with softmax-based energy functions, including a similarity-based aggregation over the training samples. In other words, diffusion models define a learned energy landscape that attracts samples toward training data — and potentially toward spurious attractors when the model cannot exactly memorize due to data overload.
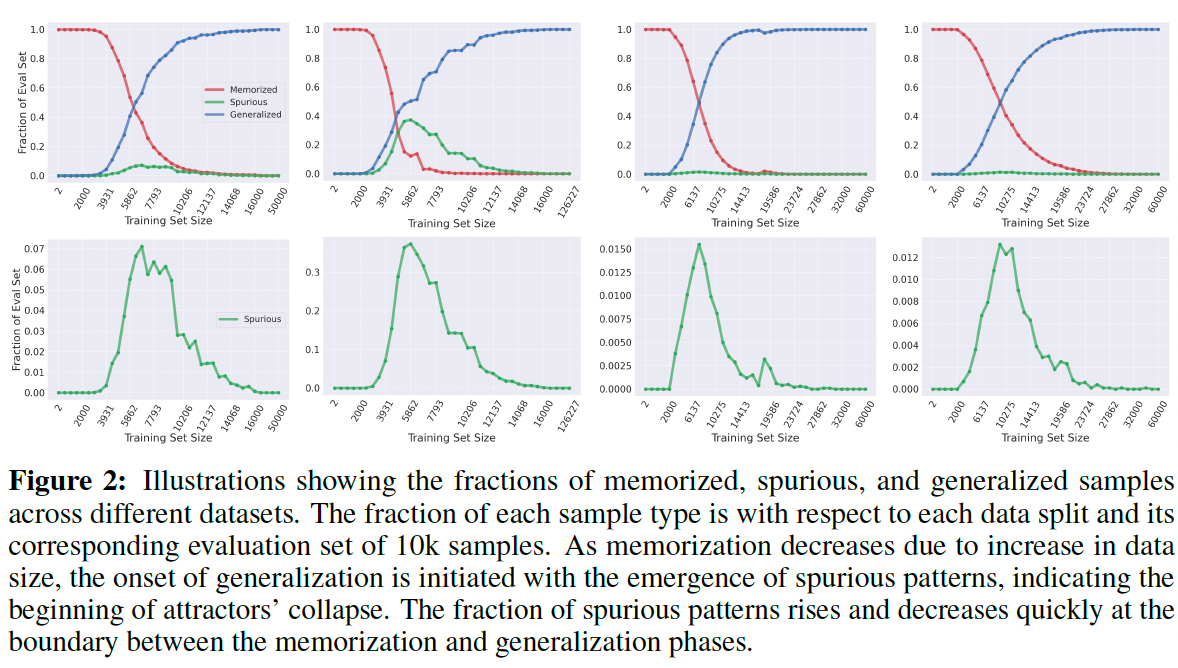
What makes the connection non-trivial is that this structure is not imposed manually — it emerges from the training objective of the diffusion model. The denoising score-matching loss, which trains the model to reverse a stochastic corruption process, ends up instantiating an energy surface with attractor-like properties.
Now, as the training dataset size increases, the nature of the learned attractors changes. In the small-data regime, the score function learned by the diffusion model has high precision and confidence near training examples, and the generated outputs tend to be direct or near-exact copies — evidence of pure memorization. The model's score landscape is steep and concentrated, and the attractor basins are narrow and centered directly on the training samples.
As the training data size increases, the model can no longer dedicate a distinct, isolated basin to each sample. The energy surface begins to interpolate. Spurious attractors emerge — regions in latent space that do not correspond to any training example, but still act as local minima. These spurious regions reflect structural overlap between training patterns. Unlike memorized samples, spurious samples are supported by the synthetic distribution learned by the model but do not occur in the training data themselves.
The authors quantify this with three theoretical constructs:
Memorization capacity: the maximum training set size for which the model primarily reproduces training data with high probability.
Spurious capacity: the size at which the model most frequently produces samples that lie outside the training set but still within the model’s learned distribution — these are not fully generalized yet.
Generalization capacity: the minimum training set size after which the model begins producing samples that are dissimilar to both the training and previously generated samples — this marks true generalization.
The transition between these regimes is not smooth but exhibits phase-transition-like behavior. Empirically, the fraction of memorized samples drops sharply, the fraction of spurious samples peaks, and then drops as generalization takes over. These transitions are detected using nearest-neighbor based metrics that measure whether a generated sample matches training data (memorization), matches synthetic but not training data (spurious), or matches neither (generalized).
Crucially, the model does not simply interpolate between samples due to overfitting noise — the interpolation is a function of structural interactions in the score landscape. The spurious attractors are formed by the aggregation of contributions from many training samples under the softmax dynamics of the score function. This is functionally identical to how modern Hopfield networks form spurious attractors when the overlap between stored patterns increases beyond a certain threshold.
Thus, the key contribution is a rigorous theoretical bridge: diffusion models operate as associative memory systems that exhibit a well-defined phase transition from pattern recall to generative abstraction. This transition is mediated by the collapse and recombination of energy attractors in the score space, governed by data distribution complexity, training set size, and model capacity.
The work doesn't merely draw analogy — it aligns the functional components of denoising score matching, softmax aggregation, and attractor dynamics into a cohesive interpretation. It frames generalization in diffusion models not as emergent from architectural inductive bias alone, but as a result of distributed attractor interference — a direct consequence of overloading the energy surface defined implicitly by the training dynamics.
https://openreview.net/forum?id=zVMMaVy2BY