
Memento: The Dawn of FineTune-Free Agent Learning
Memento: Fine-tuning LLM Agents without Fine-tuning LLMs, Mike’s Daily Paper: 27.08.25

This paper proposes a new paradigm for building LLM agents that can learn and adapt from experience, all without the crippling cost of actually fine-tuning the LLM. It's a clever fusion of classic AI and modern reinforcement learning that feels like a genuine step forward.
For a while now, the world of LLM agents has been split into two camps. On one side, you have rigid, handcrafted systems with fixed workflows. They're reliable for narrow tasks but brittle; they can't learn or adapt once deployed. On the other side, you have the "fine-tune everything" approach, where you try to bake new skills directly into the LLM's parameters using reinforcement learning. This is powerful but astronomically expensive, slow, and risks "catastrophic forgetting," where the model loses old skills while learning new ones.
This leaves us with a critical question: How can we build agents that learn continuously from their environment without the prohibitive cost of retraining the core model? The paper introduces a third way. Instead of modifying the LLM's internal, parametric knowledge, Memento externalizes learning into an adaptive memory system. The agent fine-tunes its ability to use its memory, not the LLM itself. It’s an elegant solution that offers a scalable, efficient path toward agents that acquire skills in real-time.
The Novelty: Memory as the Policy
The core innovation in Memento is to reframe the agent's learning process. Instead of teaching the LLM new tricks, the goal is to teach the agent to become an expert at referencing its own past experiences; both successes and failures. This is achieved by combining a rigorous mathematical framework with a psychologically grounded reasoning process.
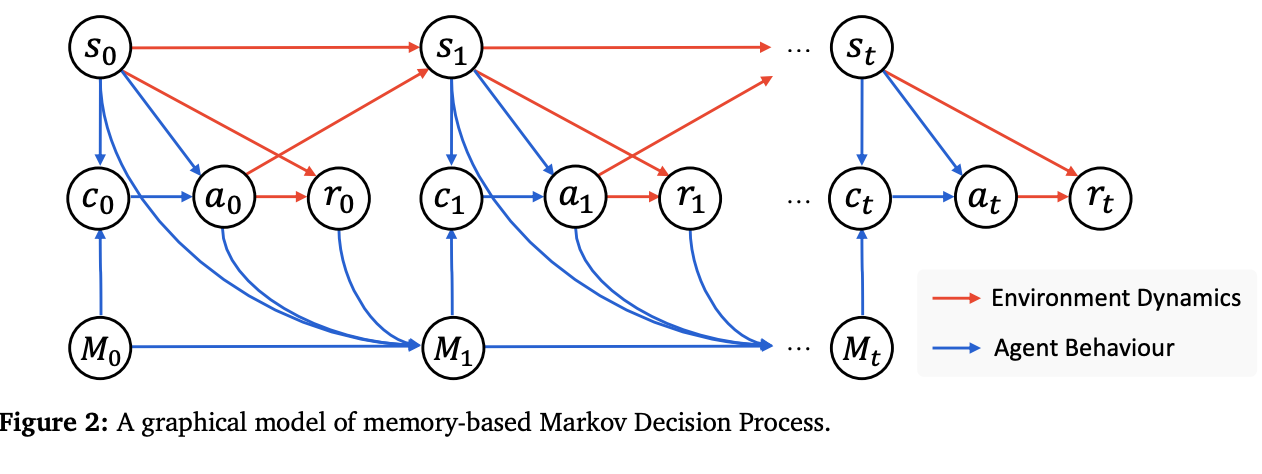
A New Formalism: The Memory-Augmented MDP
The authors' first contribution is to formally model the agent's world as a Memory-augmented Markov Decision Process (M-MDP). This is more profound than it sounds. A standard Markov Decision Process (MDP) defines how an agent should choose an action based on its current state. The M-MDP adds a new, crucial variable to the equation: the agent's memory. Now, the optimal action depends not just on the current situation, but on the entire bank of past experiences the agent has accumulated.
This formalism turns the vague idea of "learning from experience" into a solvable optimization problem. The agent's behavior is no longer just a function of its current state, but a policy that explicitly conditions on its memory.
The Engine: Case-Based Reinforcement Learning
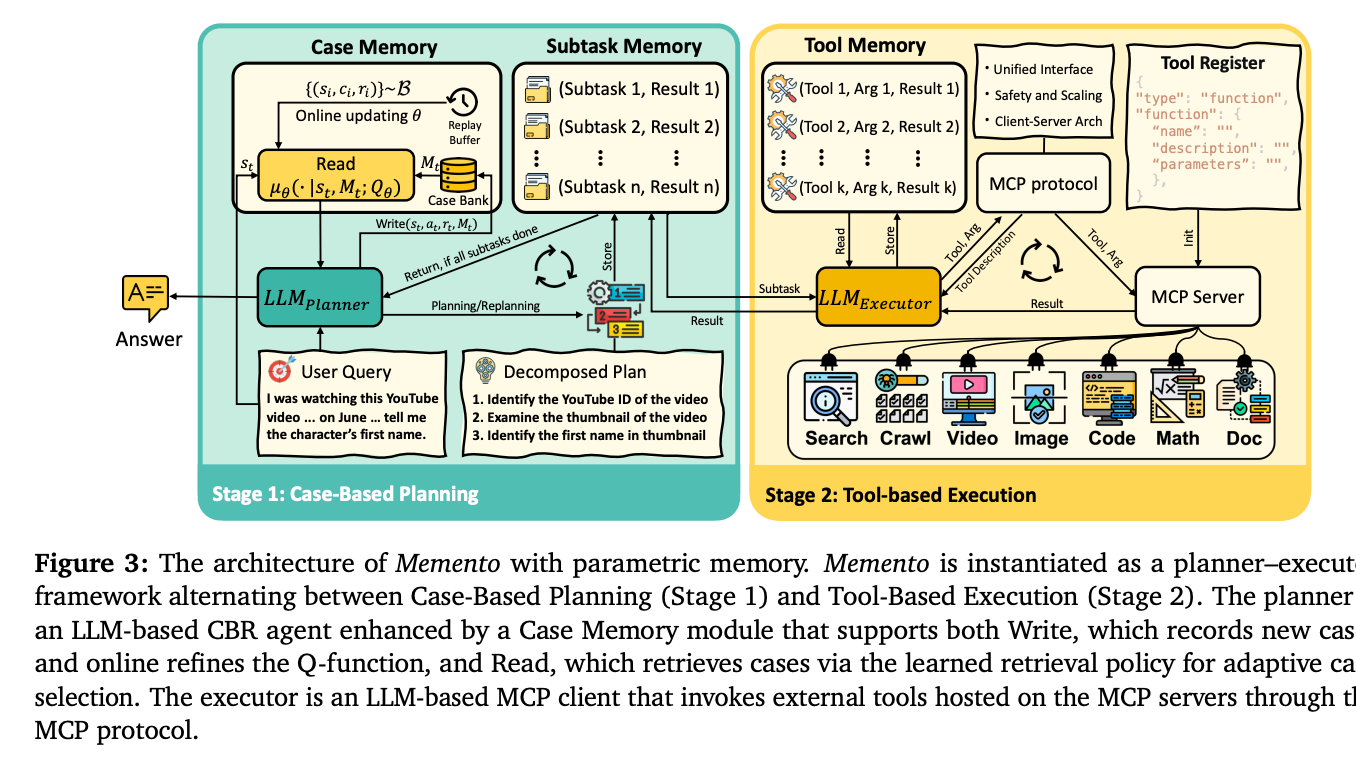
The M-MDP is the "what," but Case-Based Reasoning (CBR) is the "how." Memento implements a CBR policy where, at each step, the agent performs a two-stage process:
Retrieve: It first consults its memory, a growing "Case Bank" of past trajectories, and selects a relevant past case. A case is a simple triplet: the state it was in, the action it took, and the reward it received.
Reuse & Adapt: It then feeds this retrieved case to the LLM planner, along with the current task. The LLM's job is to adapt the solution from the old case to the new problem.
The true genius of the system lies in the retrieval step. How does it learn which case to retrieve? A naive approach might just find the most semantically similar past experience. But Memento is far more sophisticated. It learns a case-retrieval policy using reinforcement learning.
The "action" in this RL setup isn't a tool call or a line of code; it's the act of selecting a memory. The system learns, through trial and error, a value function that predicts how useful a particular past case will be for solving the current problem. This is achieved via soft Q-learning, where the agent is rewarded for selecting cases that lead to successful outcomes. The "soft" part encourages exploration, preventing the agent from getting stuck retrieving the same few memories over and over.
This learned Q-function is the "fine-tuned" part of the agent. But critically, it’s a tiny, efficient neural network—not a multi-billion parameter LLM. The agent's brain (the LLM) remains frozen, while its skill in accessing its own experience (the memory retrieval policy) constantly improves
Parametric vs. Non-Parametric Memory
Memento implements this retrieval policy in two flavors:
Non-Parametric Memory: This is the simpler baseline, where cases are retrieved based on cosine similarity. It works, but it's "dumb," treating all similar past experiences as equally valuable.
Parametric Memory: This is the full, learned approach. Here, a small neural Q-function is trained online to predict the utility of retrieving a given case for the current state. Every time the agent completes a task, it doesn't just save the experience; it uses that outcome to update its Q-function, subtly refining its understanding of which memories are most valuable. This parametric approach consistently outperforms the non-parametric one, proving that learning to retrieve is a more powerful mechanism than simply finding similar things.
Performance and Why It Matters
The results speak for themselves. Memento achieved top-1 performance on the GAIA benchmark's validation set and demonstrated significant, consistent gains across a wide range of other benchmarks like DeepResearcher and SimpleQA.
But the most important results come from the ablation studies, which systematically dismantle Memento to prove where the magic comes from:
Planning is essential: The base planner-executor architecture provides a massive lift over a simple tool-using LLM, confirming that task decomposition is key.
CBR provides an additive boost: Layering the case-based memory on top of the planner yields another consistent jump in performance across all tasks. This proves the memory system is not just a gimmick but a core contributor to the agent's success.
It generalizes: When trained on one set of tasks and tested on completely out-of-distribution (OOD) datasets, Memento showed absolute performance gains of up to 9.6%. This is crucial: learning from experience allows the agent to develop generalized problem-solving strategies that transfer to novel situations.
Memento offers a compelling new blueprint for building LLM agents. By decoupling the agent's stable, core reasoning engine (the LLM) from its dynamic, evolving experience (the adaptive case memory), it provides a computationally feasible path toward creating agents capable of genuine lifelong learning. It’s a principled framework that moves beyond ad-hoc prompting and toward a robust, mathematically grounded science of agent design.
http://arxiv.org/abs/2508.16153