
Fine-tuning LLM with RL from the angle of the memory
How many models you need to store in memory for PPO and GRPO?

Reinforcement Learning with Human Feedback (RLHF) and Model Requirements for LLMs
Introduction
Reinforcement Learning with Human Feedback (RLHF) has emerged as a powerful paradigm for fine-tuning large language models (LLMs) to align better with human values and preferences. By incorporating structured human feedback, RLHF aims to improve model outputs beyond traditional supervised learning techniques. Central to this approach is Proximal Policy Optimization (PPO), a reinforcement learning algorithm well-suited for handling the constraints of fine-tuning massive language models. However, efficient deployment requires careful consideration of computational resource demands, including the number of distinct models used and memory (DRAM) requirements.
This post provides a detailed breakdown of the models involved in RLHF with PPO, contrasts it with Group Relative Preference Optimization (GRPO), and explores the hardware demands for each method. Note that formally GRPO can’t be referred as RLHF as it doesn’t use any human feedback for fine-tune as it applies predefined rules for the reward computation.
Model Requirements for RLHF with PPO
1. Fine-tuned LLM
The fine-tuned LLM learns from human feedback by maximizing a reward signal, which is derived from interactions with a reward model and computed value functions.
Role: Generates candidate responses to prompts.
Update: Parameter updates are performed based on policy gradients computed from PPO loss.
2. Reference (Baseline) LLM
The reference LLM remains static during training and serves as a fixed baseline.
Role: Provides log probabilities for the current policy in PPO loss computation.
Importance: Ensures stable learning by preventing drastic shifts in the updated LLM’s behavior.
3. Reward Model (RM)
The reward model assigns a scalar reward to the LLM’s output based on human feedback data.
Training: Typically fine-tuned separately using supervised learning from human-labeled data.
Input: Sequences from both the updated LLM and human-preferred sequences.
Output: Scalar reward values that guide PPO training.
4. LLM for Computing Value Function
The value function approximator predicts the expected return from a given state (prompt-response pair).
Implementation: It is typically not a completely separate model but often shares weights/architecture with the updated LLM by introducing a head specifically designed to compute the value function.
Role: Essential for computing the advantage function in PPO, which guides the model's updates by quantifying the improvement of a specific action(= model parameter update) relative to the baseline model.
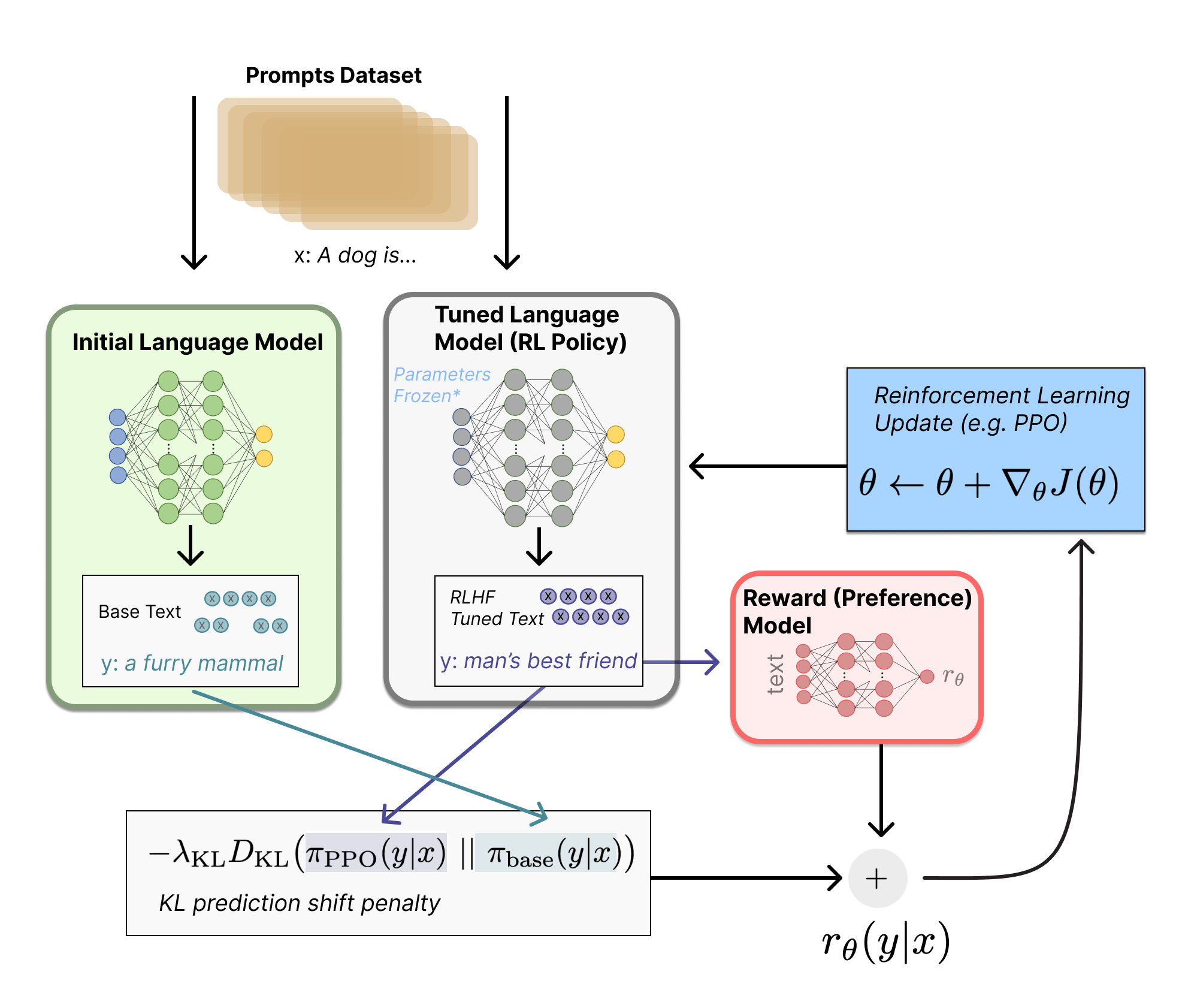
Memory and Compute Demands for RLHF
The need for four distinct models (updated LLM, reference LLM, reward model, and value function approximator) significantly impacts computational resource requirements:
DRAM Usage: Large memory footprints due to simultaneous model inference and gradient computation.
Compute Overhead: The PPO algorithm demands multiple forward and backward passes for both policy and value networks, compounding the overall compute cost.
Scaling Concerns: As LLM sizes grow (billions of parameters), memory requirements become a bottleneck, necessitating techniques such as model parallelism and mixed-precision training.
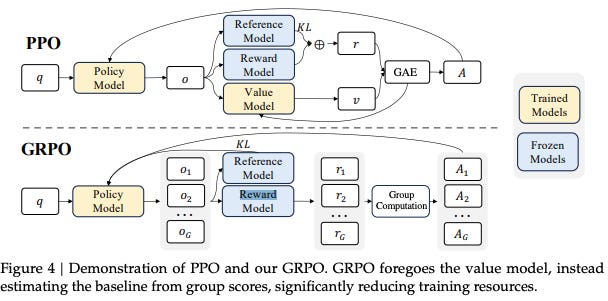
Group Relative Preference Optimization (GRPO)
GRPO is a recently proposed optimization technique that simplifies the architecture required for reward-guided learning.
Key Innovations
Model Reduction: GRPO uses only two models:
Updated LLM: Fine-tuned directly based on reward signals derived from task-specific objectives.
Reference LLM: Maintains a fixed policy for comparison.
Reward Computation: GRPO adopts a streamlined reward structure focused on task-specific outputs.
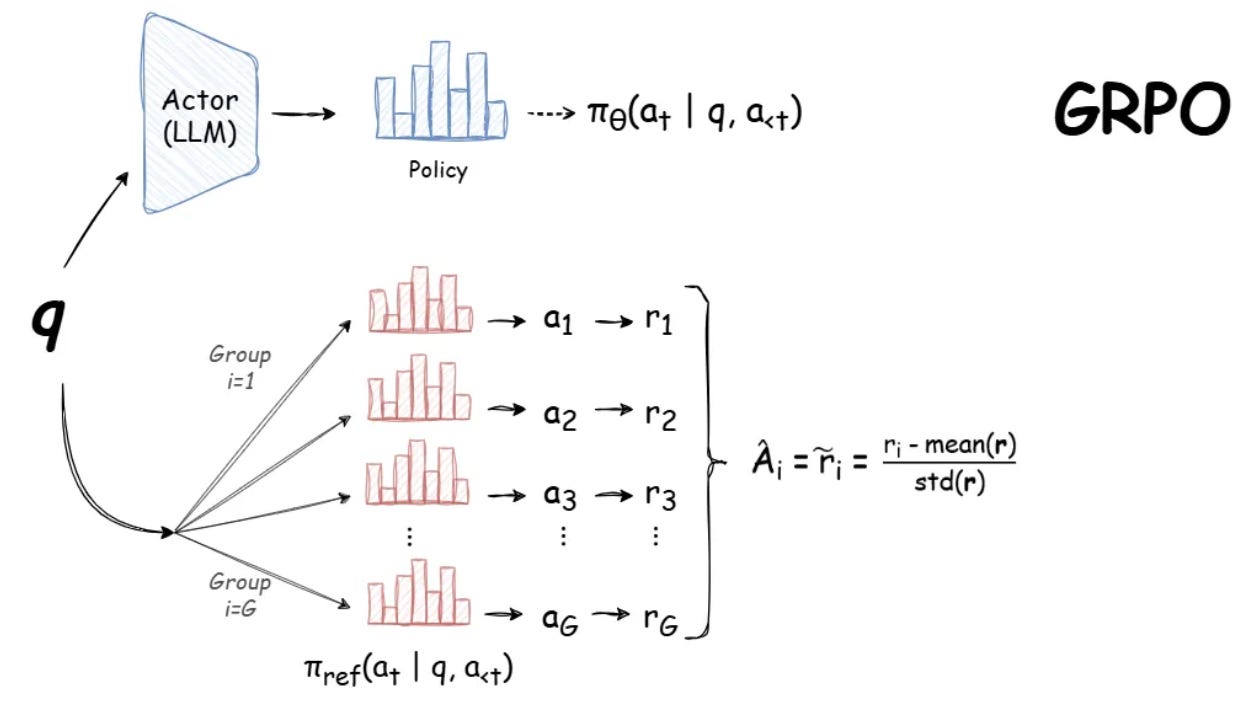
Types of Rewards in GRPO
Accuracy Rewards: The reward model evaluates whether the response is correct. For example:
In mathematical problem-solving tasks, the model must provide a final answer in a specific format (e.g., within a box) to enable reliable rule-based verification.
For LeetCode-style coding challenges, a compiler can assess correctness by executing test cases.
Format Rewards: This reward model encourages structured reasoning. The model is required to enclose its thought process between predefined tags, such as
<think>and</think>, to clearly separate reasoning steps from final answers.
More Possibilities with GRPO
Using a Reward Model: In scenarios where finer reward granularity is essential, GRPO can incorporate a separate reward model. This approach requires storing three models in memory (updated LLM, reference LLM, and reward model).
Fine-tuning the Reference Model with LoRA/Adapters: To further reduce memory requirements, the reference LLM can be fine-tuned using Low-Rank Adaptation (LoRA) or lightweight adapters. This approach necessitates storing only a single base model along with the small number additional parameters introduced by LoRA or adapters.
Advantages of GRPO
Reduced Memory Footprint: Eliminates the need for a separate reward model and value function approximator, drastically lowering DRAM requirements.
Simplified Training: Fewer models involved mean less computational complexity and synchronization overhead.
Efficiency Gains: No need to collect human-labeled data and train reward model.
Hybrid Approaches
Future work may explore hybrid methods that leverage the efficiency of GRPO while incorporating certain components (e.g., lightweight reward models) from RLHF to balance complexity and performance.
Conclusion
Both RLHF with PPO and GRPO offer powerful pathways for aligning LLMs with human preferences. While RLHF provides a comprehensive framework with fine-grained control, GRPO presents a more resource-efficient alternative. The choice between these methods should be guided by task requirements, resource constraints, and performance goals. Understanding the trade-offs in model complexity and computational demands is essential for optimizing the deployment of LLMs in real-world applications.