
Efficiently Learning at Test-Time: Active Fine-Tuning of LLMs
Mike’s Daily Paper review – 19.03.25

Introduction
Recently, the most popular method for adapting language models to a specific task is in-context learning (ICL). Essentially, we provide the model, within the prompt, with a few examples of how to perform the task, and the model "learns" how to execute it without any changes to its weights. ICL is possible due to the adaptive nature of transformers (the attention mechanism within them), which manages to "update its computation" as a function of the input.
The paper discusses a different method for adapting a model to a given task at test time (the paper somewhat mixes the concept of test and inference), which involves a light fine-tuning of the model based on the prompt it receives. Unlike ICL, the proposed method—SIFT (Selects Informative data for Fine-Tuning)—does change the model’s weights (performs a single gradient descent step). In fact, SIFT (by the way, there is also a method with this name in image processing from the pre-neural network era) proposes a method for selecting examples from the dataset for fine-tuning the model on a given prompt.
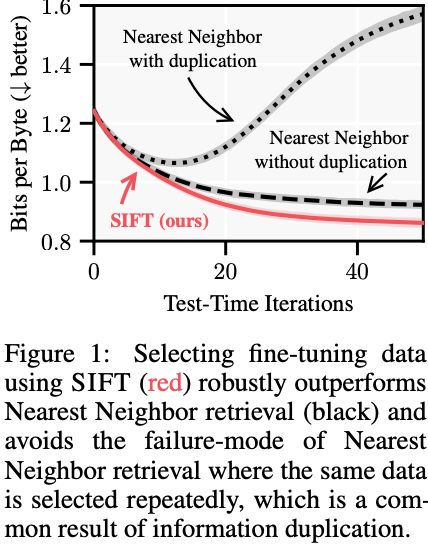
The authors argue that selecting examples closest to the prompt in latent space based on cosine distance or inner product (nearest neighbors or NN) is suboptimal and may retrieve redundant examples that harm fine-tuning performance. Instead of retrieving the most similar examples to the prompt, SIFT selects those that provide the most new information, thereby achieving better model adaptation with minimal additional computations.
Uncertainty Estimation for Guiding Fine-Tuning – Why Is This Important?
Many fine-tuning methods rely on retrieving similar examples based on cosine similarity or Euclidean distance. However, this approach is flawed: it does not distinguish between relevant and redundant data. Two very similar examples may contain the same information, and therefore, one of them does not contribute to the fine-tuning result. To solve this, the authors propose a method for estimating the model’s uncertainty in its response after fine-tuning.
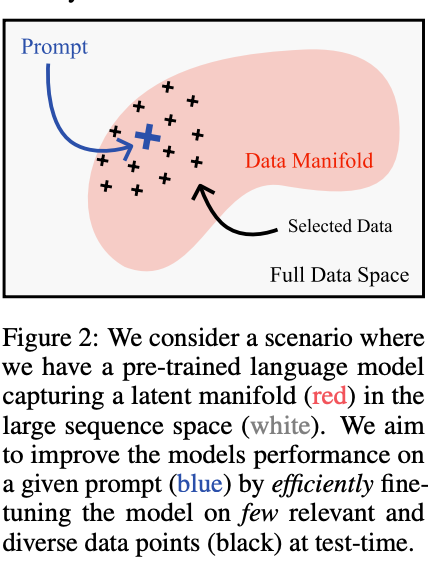
If the model is very confident in its answer after fine-tuning, adding an example will not significantly affect the result. If uncertainty is high, smart selection of examples can greatly improve model performance. The challenge is efficiently finding these examples.
Measuring Similarity in Latent Space Using a Kernel Function
As mentioned, the basis of SIFT’s selection method is measuring similarity between examples in latent space. To quantify this similarity, the authors use a kernel function, which is defined as the inner product between the latent representations of the examples(text).
This function takes two text sequences and returns a similarity score - high for similar sequences and low for different ones. Using this kernel function, they construct a kernel matrix for the selected fine-tuning examples and the prompt itself. They then define a surrogate model, whose purpose is to estimate the performance of the LLM after fine-tuning on the selected examples.

Using this model (which is somewhat mathematically non-trivial), they estimate the model’s uncertainty after adding an example x from the dataset to the set of examples used for fine-tuning. Ultimately, they select the example that minimizes uncertainty for the prompt and add it to the set of examples.
In Simple Terms, the Proposed Approach Balances Two Opposing Considerations:
Relevance: The selected examples should still be relevant to the prompt.
Diversity: The examples should not contain overlapping and redundant information.
Instead of selecting examples all at once, SIFT selects each example gradually, using the kernel function to determine its added value. The algorithm can be summarized in the following manner:
- If a new candidate is too similar to previously selected examples, it is rejected, as it does not add new information.
- If the candidate is relevant but contains new details, it is selected to reduce uncertainty.
- If the candidate is completely unrelated to the prompt, it is excluded from the process.
https://arxiv.org/abs/2410.08020