


Draft Model Knows When to Stop: A Self-Verification Length Policy for Speculative Decoding
Mike's Daily Deep Learning Paper – 14.04.25

This paper caught my eye at first glance because of the phrase "Speculative Decoding" or SD for short — something very close to my heart. I even prepared a fairly comprehensive presentation on it, which I present in various forums. SD allows increasing the text generation rate of a language model by combining the target model with a smaller, faster (and of course weaker) model. The small model autoregressively generates a few tokens, and the target model then uses these tokens to predict its next tokens in parallel. This can significantly boost the sampling rate of the large model.
The method leverages the fact that the bottleneck in the generation process is data transfer between the different types of GPU memory (in particular, the large and slow HBM vs. the fast SRAM located close to the compute units). SD performs a fast prediction with the small model, followed by parallel prediction with the large model, using the tokens generated by the small model.
But there’s a catch, of course: in order to sample from the same token distribution as the large model (while using the small model’s predictions), we need to perform something akin to rejection sampling (RS).
To recap: RS allows sampling from an easy-to-sample distribution f in order to produce samples from a different, harder-to-sample distribution g. We sample a point xxx from f, and accept it with probability equal to the ratio g(x) / f(x) (if the ratio is greater than 1, the point is always accepted). One can prove that the accepted samples follow the desired distribution g.

So in our SD case, we do something similar for tokens generated by the small model. In the second phase (parallel sampling with the large model), for each token produced by the small model, we compute the ratio of the probabilities assigned by both models and accept the small model’s token with probability equal to that ratio. As soon as the first token is rejected, the large model resumes generating from that point, and the small model is used again to produce the next speculative tokens. By the way, even the accepted tokens are reweighted — they're generated based on a mixture of the small and large model distributions.
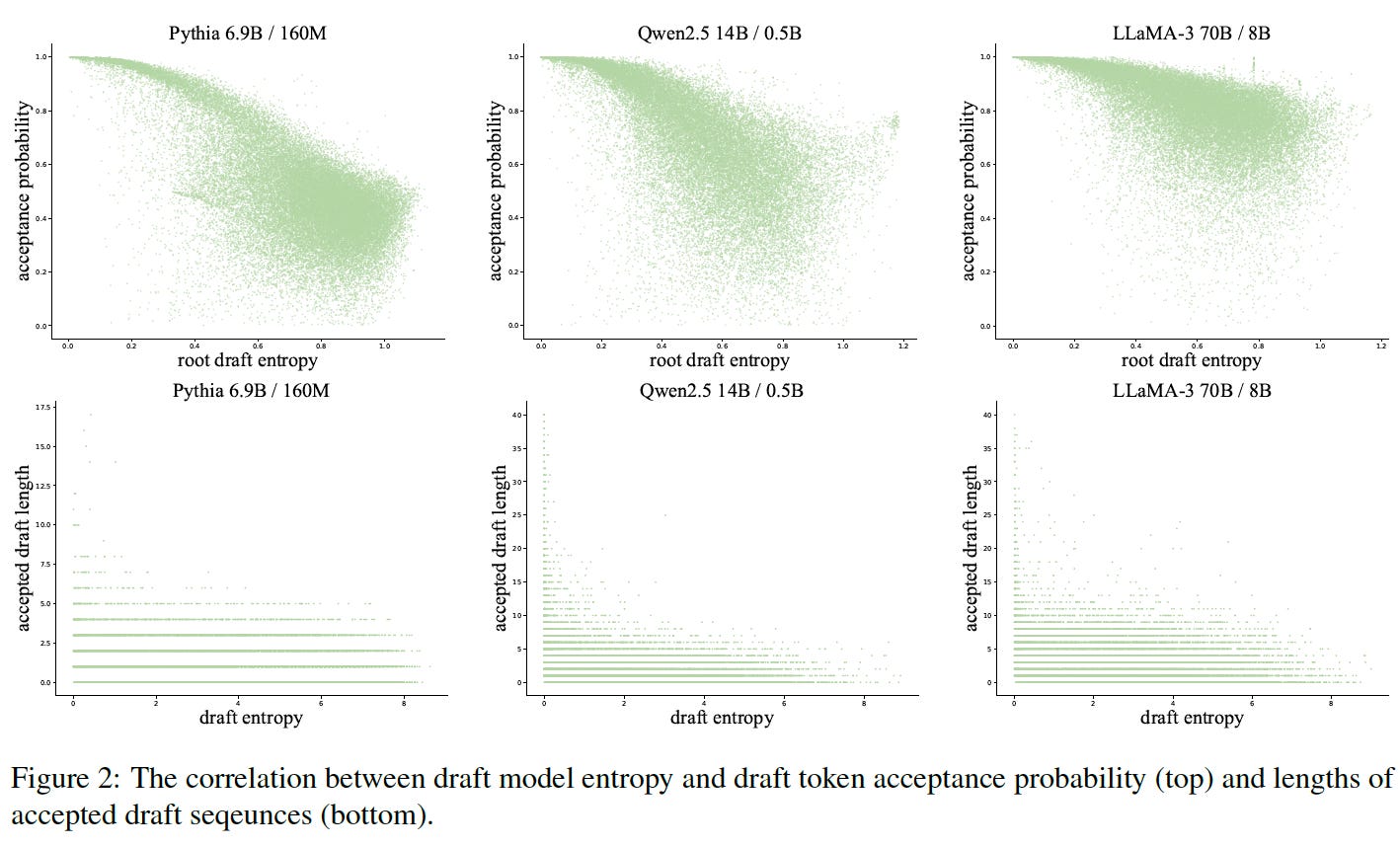
As you might’ve guessed, controlling the acceptance rate of the small model’s tokens is very important — ideally, we’d only generate tokens that will be accepted. This paper proposes a method to improve the acceptance rate.
It shows that the average acceptance rate (pretty straightforward) equals 1 minus the total variation distance (TVD) between the conditional distributions of the two models (given context). Luckily, we have access to a not-so-well-known inequality that provides a lower bound on the TVD using the difference between the cross-entropy of the two models’ distributions (for a given token given context) and the entropy of the small model.

But of course, we can’t compute the cross-entropy between these distributions during the large model sampling phase — because we sample all tokens simultaneously and don’t know the conditional distribution for each token in advance. So, the paper estimates this cross-entropy using a time-averaged estimate: a constant (slightly greater than 1) times the entropy of the small model’s token. Once we have this cross-entropy, we can estimate the acceptance rate for each small-model token before sampling with the large model. This allows us to set the number of speculative tokens to generate — we just keep generating until the estimated acceptance rate drops below a certain threshold.
Nice idea overall, but I think the choice of the constant in the final step isn’t optimal, and I hope to see future work that improves this aspect of the method.
https://arxiv.org/abs/2411.18462