


DINO-WM: World Models on Pre-trained Visual Features Enable Zero-shot Planning
Mike's Daily Paper Review: 01.07.2025

Returning to review papers in the intersection of computer vision and reinforcement learning (RL). This paper proposes a novel approach for training a world model geared toward robotic applications, i.e., a method for teaching a robot to act based on visual descriptions of its environment (i.e., images).
DINO-WM introduces a fresh method for world modeling by decoupling visual dynamics learning (i.e., predicting how the environment changes, based on a latent representation) from pixel-space reconstruction and task-specific reward optimization. Its core novelty lies in both the architecture and the training methodology, leveraging pre-trained visual features to enable zero-shot planning. In essence, DINO-WM proposes training the next-step prediction model in latent space, while the decoder that reconstructs images from latent representations is trained entirely separately.
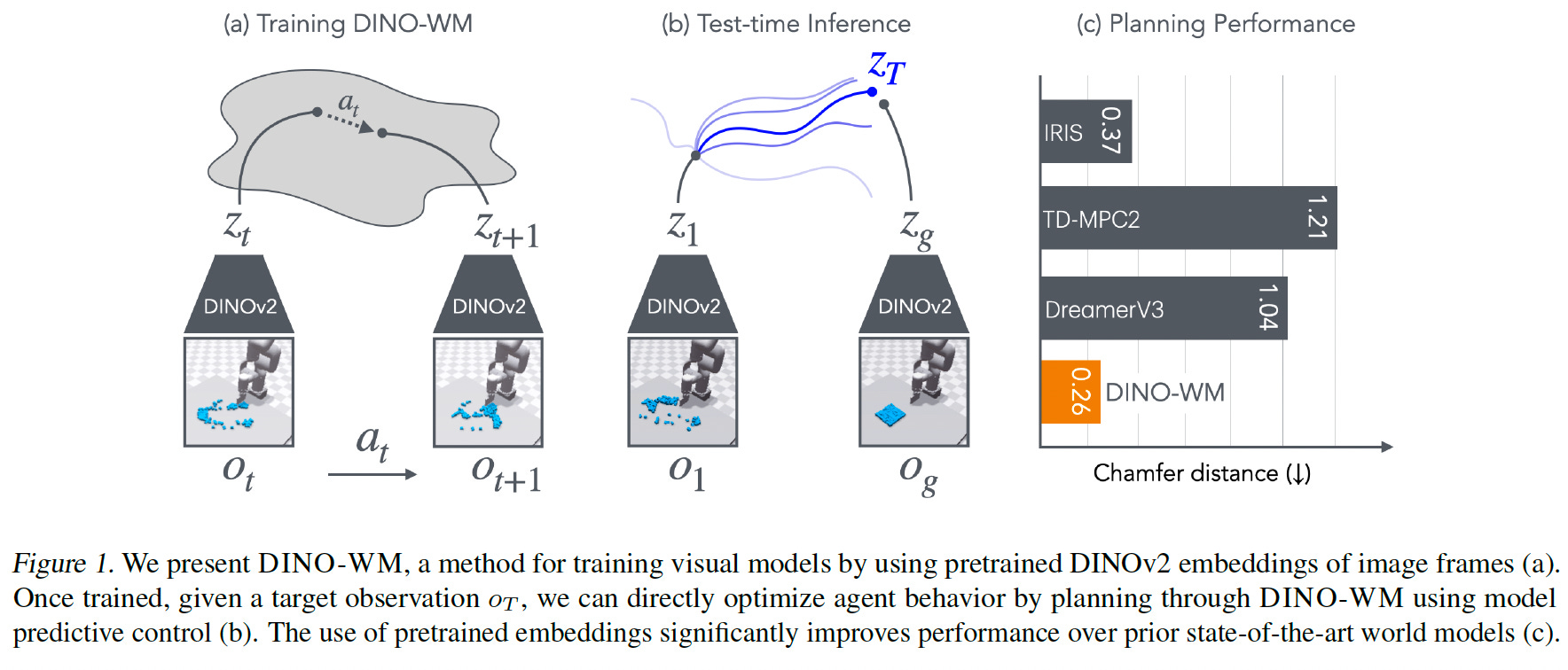
Traditional world models often struggle with either the computational cost of pixel-level prediction or with limitations in latent-space models that are tied to image reconstruction objectives. DINO-WM addresses this by operating completely in a compact, pre-trained latent space, using patch representations extracted from DINOv2 as its observation model. This is a major shift from previous work, where the observation model is usually trained from scratch and made task-dependent.
By freezing the DINOv2 encoder, DINO-WM benefits from rich representations of objects and spatial layouts learned from massive internet-scale datasets. This makes the observation model task- and environment-agnostic.
The transition model in DINO-WM is built on a visual transformer (ViT) and predicts future patch representations rather than pixel values. Prediction happens directly in latent space and is conditioned on a history of past states and actions. A key technical feature is the use of causal attention within the ViT.

Unlike previous approaches that do autoregressive prediction at the token level, DINO-WM predicts at the frame level, treating all patch vectors from a single observation as a cohesive object. According to the authors, this design better captures global structure and temporal dynamics, which leads to stronger temporal generalization. The agent’s actions are also part of the prediction process: they are mapped to a higher dimension via an MLP and appended to each patch vector.
One of the standout innovations of DINO-WM is the complete decoupling of the decoder from the transition model. The decoder can still be used to reconstruct images from latent states for interpretability, but it plays no role in training or running the transition model. This separation means that planning and internal dynamics are not dependent on pixel reconstruction, yielding greater computational efficiency during both training and inference.
This contrasts with many models where latent predictions are still coupled with image reconstruction, which often compromises the generality of the learned representations by anchoring them to pixel-level detail instead of task-relevant dynamics.
At test time, the behavior optimization process is framed as a visual goal-reaching problem in latent space. The planning loss (i.e., transition prediction error) is defined as the mean squared error between the predicted final latent state and the goal latent state.
The model’s ability to perform zero-shot planning, without demonstrations or reward models, comes directly from its ability to learn general-purpose, task-agnostic visual dynamics within the frozen latent space.
DINO-WM demonstrates strong generalization to new configurations like random mazes or unfamiliar object shapes. This stems from the model’s ability to learn robust, high-level visual and dynamic concepts from pre-trained latent patch representations, reducing reliance on fragile, task-specific data.
In summary, DINO-WM’s contribution lies in the combination of:
A frozen, pre-trained patch encoder from DINOv2 is used as an observation model
A frame-level ViT-based transition model operating purely in latent space
A full decoupling of internal dynamics from pixel-level reconstruction
This architecture enables learning robust, general-purpose visual dynamics from offline data only, which results in effective zero-shot planning and strong generalization across diverse environments.