
Diffusion Models for Non-autoregressive Text Generation: A Survey - paper review
Mike's Daily Article: 16.01.25

Today we'll review a survey from a year and a half ago about a field (family of techniques) so naturally it (the review) will be quite brief. The survey is about non-autoregressive text generation methods, meaning not token after token but rather an entire sequence. The methods we'll discuss generate text in several iterations, but this isn't done in an autoregressive way - for example, these methods can generate token number 78 before token number 24.
Okay, many of you probably thought about generative diffusion models after I mentioned iterative methods, and you're not wrong here. In this brief review, I'll explain concisely how text can be generated using diffusion models. As you probably remember, diffusion models are trained to remove noise from noisy data through iterations. In other words, the model is trained to remove small amounts of noise from the data until reaching clean data, and thus after training, the model can generate data from pure noise in several iterations.
But how can we add noise to text that lives in a discrete space (i.e., tokens)? There are two broad approaches: the continuous approach and the discrete approach. In the continuous approach, which is similar to the standard generative diffusion models, we don't operate in discrete space but in the embedding space. In the continuous approach, we transform our text into a continuous embedding vector, but unlike a regular encoder, we transform each token into its vector representation separately from the others(non-contextualized embedding). Then we train a diffusion model to generate embeddings of texts similar to the way latent diffusion models are trained. It means that noise addition and denoising model training occur in the embedding space, with the ultimate goal being to predict the tokens from the embeddings generated by the latent diffusion model after noise cleaning.
The second family of methods is to perform noise addition in the discrete space. Obviously, the noise can't be continuous, so what can be done is to change token values (for example, to [mask] token) with a certain probability, with the goal being to turn all tokens into [mask] in the final iteration. A diffusion model at iteration i is trained to predict the tokens from the previous iteration, whereas during inference, generation starts with all tokens equal to [mask] and the model gradually turns them into text.
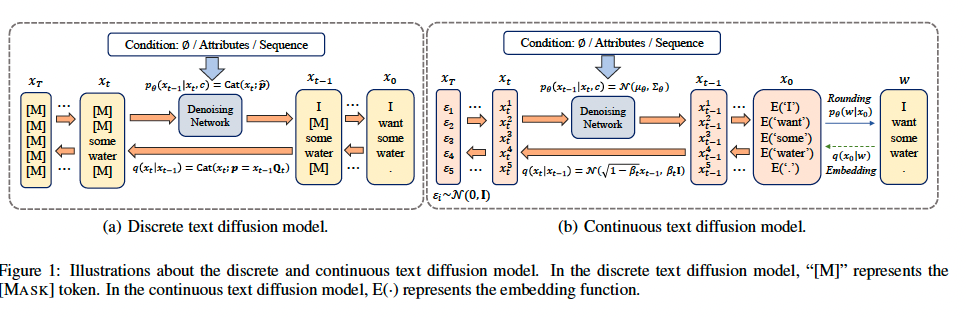
Of course, the “way tokens are noised” in each iteration is a hyperparameter equivalent to the noise schedule in regular diffusion models. It turns out that the noising method can be described by a matrix. Each token can be represented by a probability vector (over the token dictionary) so a token from iteration i can be represented as the inner product of its representation in iteration i-1 by a stochastic matrix Q_i (sum of rows and columns is 1). Q_i is the most important hyperparameter in discrete diffusion models.
It turns out this is quite an active research field although these models haven't yet reached the performance of autoregressive language models. But I'm not ruling out that this might still happen because these models can work at higher throughput than autoregressive models (for a modest number of iterations).
https://arxiv.org/abs/2303.0657