
Daily Paper from Mike's Archives(19.12.24)
Large Concept Models: Language Modeling in a Sentence Representation Space

Introduction:
A second paper (also presented at NeuriPS2024) from Meta proposing a revolutionary concept for language models. While yesterday's paper suggested abandoning the standard tokenizer in language models, today's paper proposes abandoning the next-token prediction we've become so accustomed to in LLMs.
Background:
As you probably remember, LLMs are trained (in pre-training and SFT) by maximizing the likelihood of training dataset D, meaning maximizing the probability of generating D with the trained model. To do this, we maximize (with respect to our language model parameters) the probability of each example in D. Since each piece of data consists of tokens, it can be expressed using Bayes' law as a product of conditional probabilities of each token given the previous tokens (i.e., the context). And that's how we arrive at token prediction given context in both training and inference.
Paper’s Main Idea:
The paper emphasizes that we(humans) don't think "token by token" but in concepts when building our speech (while speaking). The paper proposes applying this approach to language models where a concept is defined as a sentence. In other words, the authors propose training a model to predict the next sentence instead of predicting the next token that we're used to in standard language models.

But how do we predict a sentence, given it's discrete and for even a modest sentence length, the number of possible values becomes exponential and too large to perform prediction on (i.e., softmax of enormous size). So the paper suggested performing the next “concept” prediction in a continuous plane and proposes training a model, named Large Concept Model or LCM, to predict the next sentence embeddings given the embeddings of previous sentences in the context window. The paper examines several loss functions, the simplest being L2 between the ground-truth embedding and the predicted one (there are more interesting ones in section 2.4.1 of the paper).
Another way the paper proposed to build the next sentence embedding is training a conditional diffusion model (a very nice idea in my opinion) to predict its embedding.
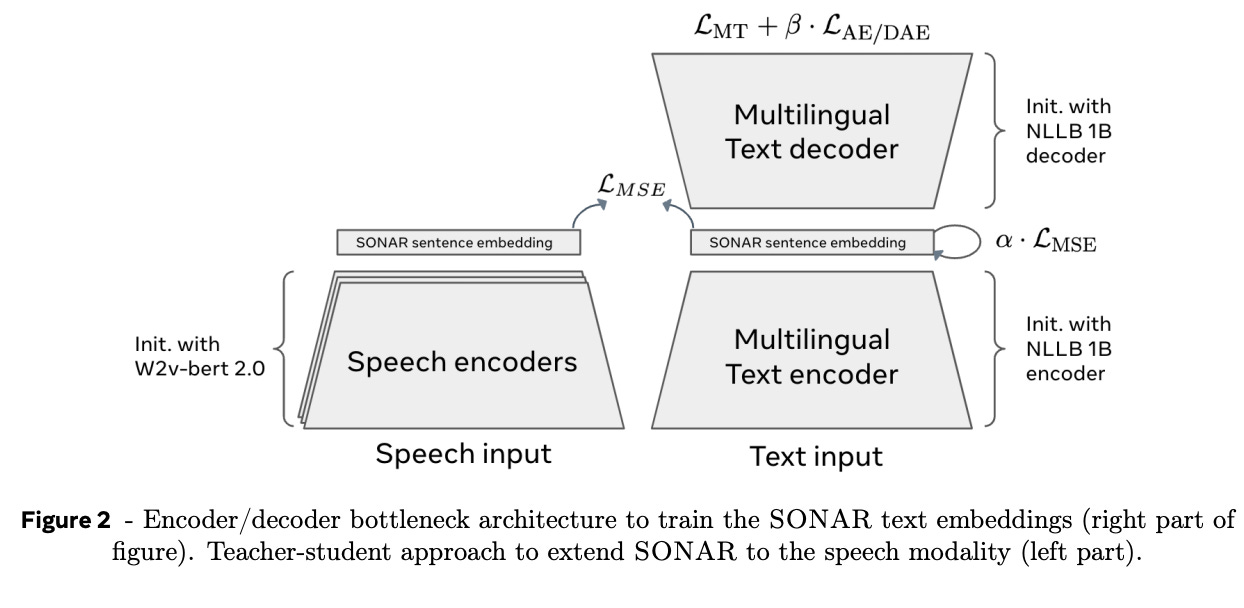
The embedding is built by an embedder model that remains fixed during training. In addition to the embedder (which is an encoder), there is a decoder that converts the concept (its embedding) to text.
Pretty nice paper, written quite clearly, just a bit too long in my opinion... https://arxiv.org/abs/2412.08821