
Contrastive Learning Techniques in NLP
A short survey about contrastive learning methods used in NLP

Introduction:
In recent years, contrastive learning has emerged as a powerful approach to representation learning, particularly in computer vision and natural language processing (NLP). Its ability to produce robust, meaningful representations of data has driven advances in various NLP tasks, from text classification to machine translation. This blog explores the fundamentals of contrastive learning, its application to NLP, and the strategies for building positive and negative examples tailored to specific tasks.
Representation Learning and Contrastive Learning: A Perfect Pair
Representation learning aims to extract meaningful features from raw data that can serve as the foundation for various downstream tasks. In NLP, these features typically encode semantic, syntactic, or contextual information about text, enabling models to generalize effectively across tasks.
Contrastive learning, a subset of representation learning, achieves this by maximizing the similarity between similar examples (positive pairs) and minimizing it between dissimilar examples (negative pairs). This method generates embeddings that cluster semantically similar instances while pushing dissimilar ones apart in the representational space. The result is a rich embedding space that reflects the intrinsic structure of the data.
What Is Contrastive Learning?
Contrastive learning leverages the relationships between pairs of data points. It is often implemented using the following principles:
1. Positive and Negative Pairs
Positive pairs are related examples, such as different augmentations of the same sentence, paraphrases, or translations. Negative pairs, conversely, are unrelated examples, such as sentences from different contexts or topics.
2. Contrastive Loss
The core of contrastive learning lies in its loss function, which quantifies the similarity of positive pairs while penalizing the similarity of negative pairs. The two most common loss functions are:
Triplet Loss: operates on triplets of samples: an anchor sample x_a, a positive sample x_p (similar to the anchor), and a negative sample x_n (dissimilar to the anchor)
InfoNCE (Noise-Contrastive Estimation): A variant that uses a softmax function to maximize the relative similarity of positive pairs within a batch.
3. Augmentation and Sampling for Positive Pair Construction
Data augmentation techniques are usually used to create variations of the same instance to serve as positive examples. Sampling strategies ensure a diverse set of negative pairs to improve the model’s discriminative ability.
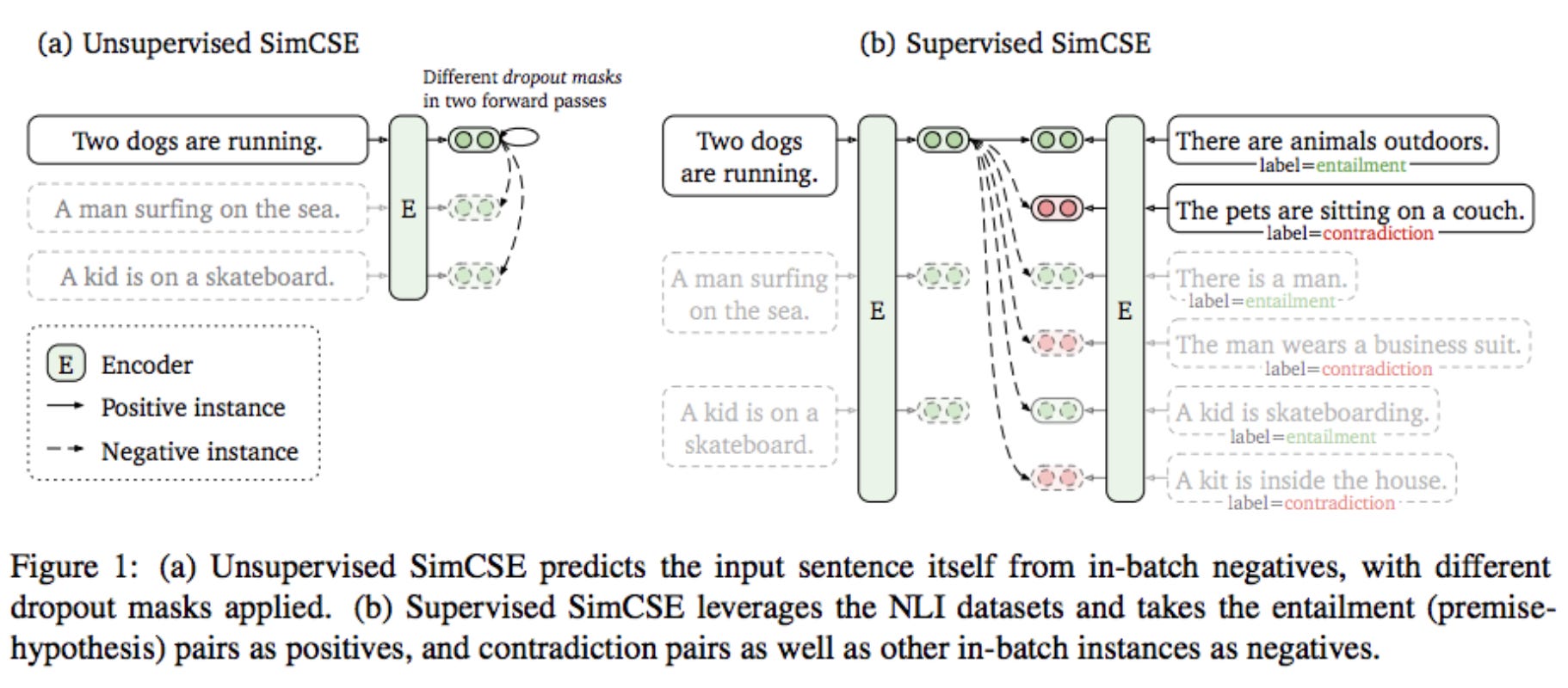
Applications of Contrastive Learning in NLP
Contrastive learning has proven invaluable across a wide array of NLP tasks. Let’s examine its role in some key applications:
1. Text Classification
By training embeddings that separate different classes, contrastive learning improves classification tasks like sentiment analysis, spam detection, or topic classification. Positive pairs consist of texts from the same class, while negatives come from different classes.
Contrastive learning ensures that representations of samples within the same category are close in the embedding space, making classifiers more robust to noise or distribution shifts.
Tasks like fake news detection or language detection also benefit from such fine-grained, contrastive representations.
2. Question Answering
Contrastive learning ensures that embeddings of questions and their corresponding answers align closely, while unrelated question-answer pairs are kept apart. This approach enhances retrieval-based systems by providing more precise matches between queries and answers.
In open-domain question-answering systems, contrastive learning improves the ranking of retrieved answers by ensuring semantic closeness of correct answers to the question.
Variations of this approach are also used in conversational AI to align question-answer pairs dynamically based on context.
3. Machine Translation
For bilingual sentence embeddings, positive pairs can be translations of each other, while negative pairs are unrelated sentences from either language. Contrastive learning ensures semantic alignment across languages.
This technique facilitates cross-lingual search, translation quality estimation, and multilingual transfer learning by aligning multilingual embeddings in a shared space.
Contrastive learning also aids in training domain-specific translation systems by focusing on contextually accurate pairs.
4. Named Entity Recognition (NER)
In NER, contrastive learning helps distinguish named entities by training embeddings that cluster similar entities (e.g., locations) and repel dissimilar ones (e.g., locations versus organizations).
By creating entity-specific embeddings, this method improves recognition in low-resource settings where labeled data is sparse.
Contrastive learning also supports cross-domain NER by aligning entity representations across different datasets or domains.
5. Text Similarity and Retrieval
Tasks like document retrieval, duplicate detection, and paraphrase identification rely on robust similarity measures. Contrastive learning excels in these scenarios by creating embeddings that emphasize semantic similarity while distinguishing subtle differences.
In legal or medical document retrieval, contrastive learning ensures precise matching of case laws or patient records based on context.
Paraphrase identification tools like Quora Question Pairs utilize contrastive embeddings to detect semantically equivalent yet syntactically different sentences.
Building Positive and Negative Examples for NLP Tasks
The success of contrastive learning hinges on the quality of positive and negative examples. Below, we outline strategies to construct these pairs for common NLP tasks:
1. Sentence Embeddings
Positive Pairs: Use data augmentations such as paraphrasing, back-translation, or dropout masking to create variations of the same sentence. Paraphrased versions ensure semantic equivalence, while back-translation adds linguistic diversity.
Negative Pairs: Use unrelated sentences from the dataset or employ hard negatives—sentences that are contextually similar but semantically different. For example, sentences like "The cat is on the mat" and "The dog is on the mat" might serve as hard negatives.
2. Text Classification
Positive Pairs: Pair texts from the same class, such as two positive reviews or two news articles about the same topic. Leveraging labeled datasets ensures high-quality pairs.
Negative Pairs: Pair texts from different classes, like a positive review and a negative one. Using adversarial examples—slightly modified texts designed to fool classifiers—enhances robustness.
3. Question Answering
Positive Pairs: Pair a question with its correct answer or semantically equivalent answers. Contextual variations of the same answer (e.g., "Paris is the capital of France" and "France's capital is Paris") enrich the training set.
Negative Pairs: Pair the question with irrelevant answers or distractor options. For example, pairing "What is the capital of France?" with "Berlin is the capital of Germany" creates meaningful negatives.
4. Machine Translation
Positive Pairs: Use parallel sentence pairs from bilingual corpora. For instance, "Hello, how are you?" in English and "Hola, ¿cómo estás?" in Spanish.
Negative Pairs: Use unrelated sentences from either language or mismatched sentence pairs from the parallel corpus. Negative pairs could also involve translations with subtle context errors to improve model discriminability.
5. Named Entity Recognition
Positive Pairs: Pair entities of the same type, such as "New York" and "Los Angeles" (locations) or "Apple" (the company) and "Microsoft." Contextual similarities, like "Barack Obama" and "Joe Biden," add value.
Negative Pairs: Pair entities from different categories, such as "New York" (location) and "Google" (organization). Pairing non-entities or irrelevant tokens provides additional learning signals.
6. Text Similarity and Retrieval
Positive Pairs: Pair semantically similar sentences, like paraphrases or questions with the same intent. Examples include "How do I reset my password?" and "What is the process to change my account password?"
Negative Pairs: Pair semantically different sentences, such as unrelated questions or contradictory statements. Including near-duplicates with slight contextual changes enhances discriminative learning.
High-quality positive and negative pairs amplify the model’s ability to learn nuanced distinctions and meaningful similarities, ensuring optimal performance across NLP tasks.
Challenges and Future Directions
While contrastive learning has shown remarkable promise, it is not without challenges:
Hard Negative Sampling: Identifying negatives that are challenging yet informative for the model can be computationally expensive.
Data Augmentation: Generating high-quality positive pairs without introducing noise remains a challenge, especially for tasks requiring nuanced understanding.
Scalability: Applying contrastive learning to large datasets with high-dimensional embeddings demands significant computational resources.
Conclusion
Contrastive learning is reshaping the landscape of NLP by offering a robust framework for representation learning. By carefully constructing positive and negative examples, it has been successfully applied to tasks ranging from text classification to machine translation. As researchers continue to refine techniques for building effective pairs and integrating contrastive learning with other paradigms, its impact on NLP will undoubtedly deepen, driving the next wave of advancements in natural language understanding and generation.