


A Paper Review: Anchored Preference Optimization and Contrastive Revisions Addressing Underspecification in Alignment
From Mike's Archives, Mike's Daily Article - 07.01.25

Introduction:
Today's paper discusses an improvement to an alignment method for language models called DPO, which belongs to the RLHF (Reinforcement Learning with Human Feedback) family of techniques. As you remember, RLHF is one of the stages (usually the last) in training LLMs, along with pretraining and Supervised Fine Tuning (SFT).
RLHF Fundamentals:
RLHF's goal is to show the model the difference between preferred (by humans) and less preferred responses. In more mathematical terms, RLHF trains the model to maximize the ratio between the score of the more preferred (better) response to a less preferred one. Classical RLHF method Proximal Policy Optimization adds a regularization term to the maximization objective that tries to keep the learned policy (like a trained LLM) close to the initial LLM (proximity is calculated using KL divergence on the distribution of tokens predicted by both models).
The score is computed using a reward model trained (in the stage prior to RLHF) to estimate the "quality" of the response to a given question. In other words, a reward model R should give a high score to a good response and a low score to a less good response. The model is trained on pairs of good and not-so-good responses to questions, where typically the responses are labeled by human annotators (sometimes powerful language models are used for this labeling).
DPO Methods:
It turned out that the PPO optimization objective could be approximated without training a reward model. In the last two years, several papers have proposed methods that can manage without a reward model. One of them is DPO, which stands for Direct Preference Optimization. With DPO, the reward function r_dpo is defined as the logarithm of the ratio between the policy (the predicted token distribution measured by the model or likelihoods) for the optimized model (being fine-tuned) to that of the initial model. DPO's training objective is to maximize the expectation (over the dataset of question-answer pairs) of the difference of r_dpo between preferred and less preferred responses.
Main Paper Ideas:
The main point of the paper is the observation that optimizing DPO's objective function can affect the ratio of likelihoods of preferred responses w to less preferred ones l in different ways. It can increase the difference between them (which is its stated goal) but it can increase p_w more than it increases p_l, or decrease p_l more than it decreases r_w. These scenarios might lead to very different models. The paper notes that a preferred response isn't necessarily better than what the model produces before alignment. In this case, DPO might harm the model's performance.
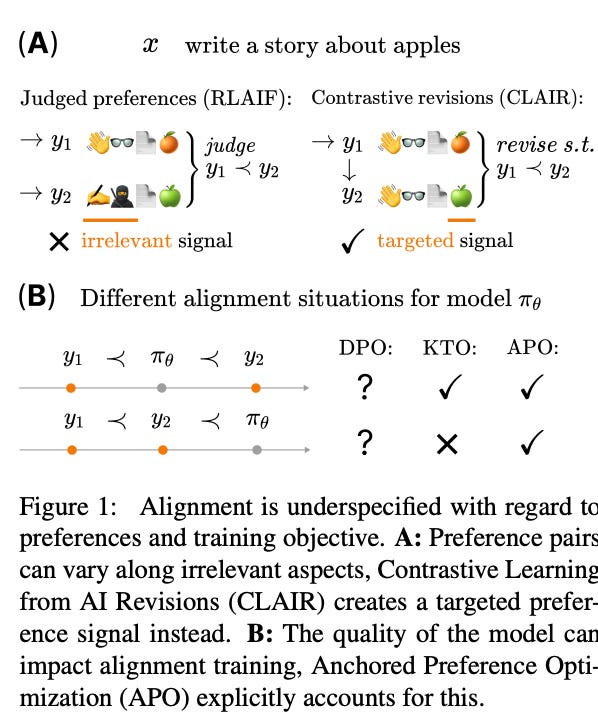
The paper examines the different cases of r_dpo values for responses w and l (preferred and less preferred respectively) and constructs two objective functions for DPO that might lead to better performance for these cases. The training method optimizing these functions was named Anchored Preference Optimization or APO. The first proposed function increases the policy value (response likelihood) when the current value of r_dpo for w is close to 0 (w has lower likelihood for the initial model) and further decreases the likelihood of the less preferred response if r_dpo for l is close to 0.

The second proposed function, on the other hand, decreases w's likelihood when r_dpo is close to 0 for w and increases the difference between the likelihoods of w and l when the difference between r_dpo for w and l is close to 0. All this is aimed at making the language model trained using DPO converge to a better solution.
There's something else interesting in this paper. The authors claim that for DPO to work better, both responses (w and l) need to be relevant to the question and one should be "just a little" better than the other. In other words, like in contrastive learning, it's better to train the model on hard negatives.

The authors propose a method for identifying (and building a dataset of) preferred and less preferred responses by creating a preferred response from any relevant response by using an LLM that improves the response (with an appropriate prompt). Another method the authors suggest is to use two responses from the trained model (with DPO) and apply a language model aimed at determining which response is better (called an on-policy judge). One can also build a dataset offline with a third language model and a judge model.
Long review - I hope you survived...